Image in Human


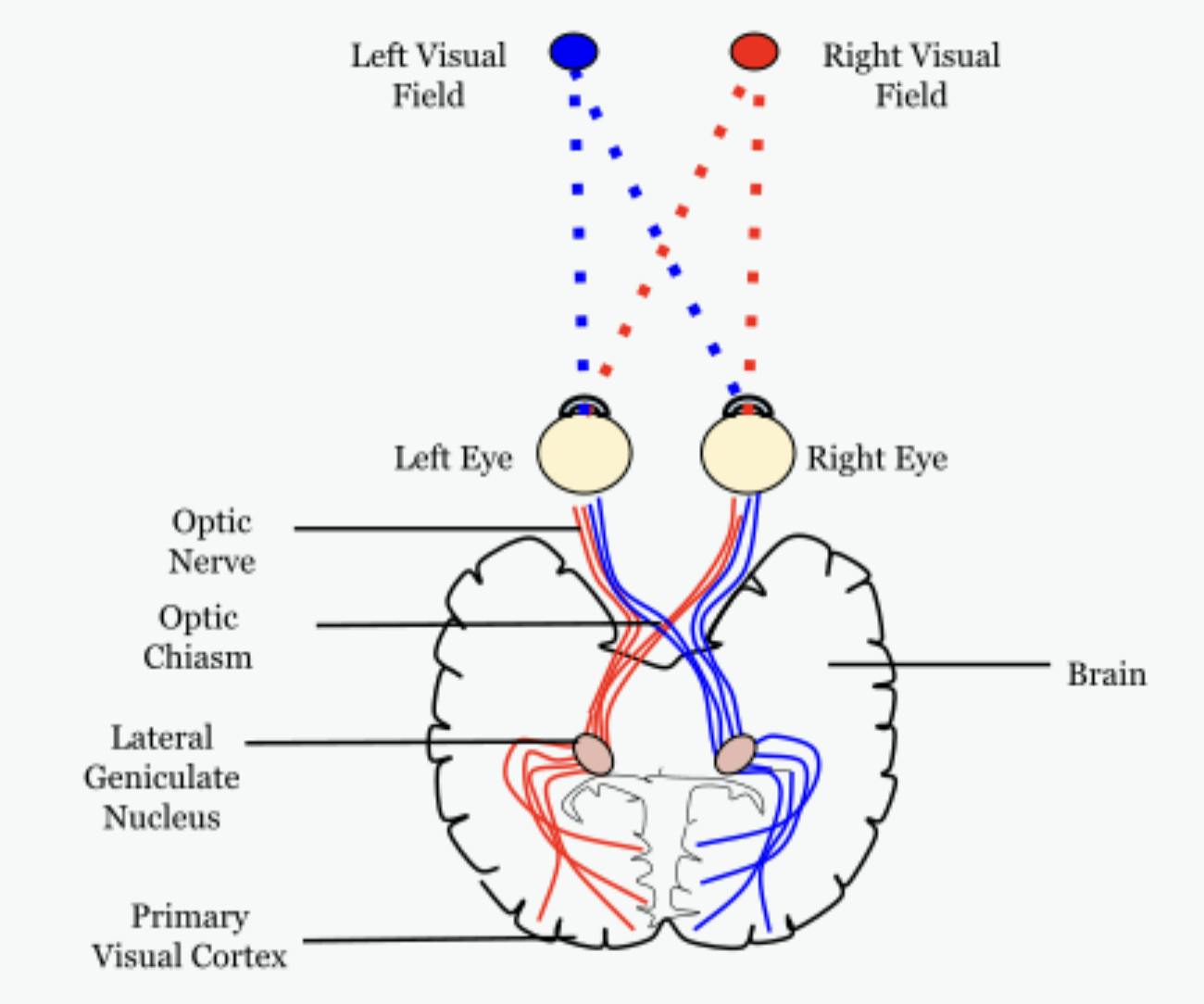
Here's a simplified flowchart of the visual processing pathway:
Retina:
Light enters the eye and is focused onto the retina at the back of the eye.
Retinal cells, including rods and cones, convert light into electrical signals.
Optic Nerve:
- Electrical signals from the retina travel through the optic nerve to the brain.
Primary Visual Cortex (V1):
Signals reach the primary visual cortex (V1) in the occipital lobe.
Basic visual information like edges, shapes, and contrasts is processed here.
Secondary Visual Cortex (V2):
- Information from V1 is further processed in the secondary visual cortex (V2) for more complex feature extraction.
V4 (Color and Form Processing):
- Some visual information branches off to area V4, specialized in color and form processing.
MT (Motion Processing):
- Another pathway leads to the middle temporal area (MT), which processes motion-related information.
Dorsal Stream (Where Pathway):
From V1, V2, and MT, information travels through the dorsal stream (where pathway) to areas like 7A.
7A in the posterior parietal cortex processes spatial information, and attention, and coordinates visuospatial tasks.
Ventral Stream (What Pathway):
Simultaneously, visual information from V1 and V2 is directed to the ventral stream (what pathway).
This pathway includes areas like V4 for color/form and continues to higher visual association areas for object recognition and identification.
Integration and Higher Processing:
Multiple visual areas interact, integrating information for higher-level processing.
The brain combines information from different streams for perception, allowing us to recognize objects, and scenes, and make sense of visual input.
Lateral Geniculate Nucleus (LGN):
LGN stands for the Lateral Geniculate Nucleus, which is a part of the thalamus, a region located deep within the brain. The LGN is a crucial relay center in the visual pathway that plays a significant role in transmitting visual information from the retina to the primary visual cortex (V1) located in the occipital lobe.
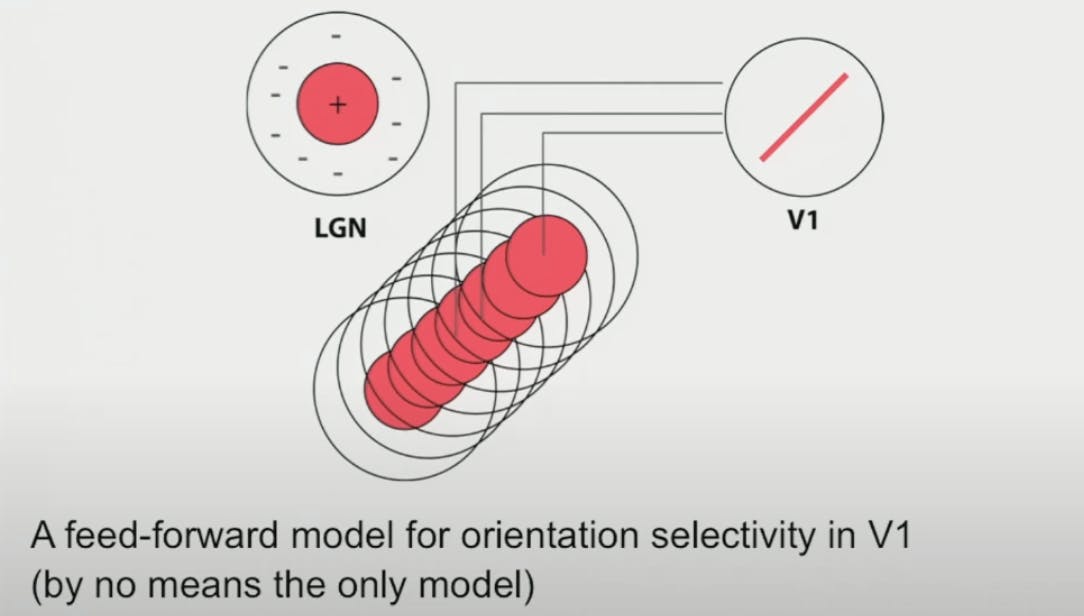
Simple cells
If we record the activity of neurons in the Retina or LGN we find center-surround receptive fields, these are circular receptive fields that have an area in the center that excites the neuron and an area surrounding that inhibits the neuron
What Hubel and Wiesel said was if we put together multiple LGN cells whose receptive fields align along certain orientations, and then if we combine the response of these neurons together we get a neuron that has orientation tuning in V1 (Note: This is not the only model there are other models as well )
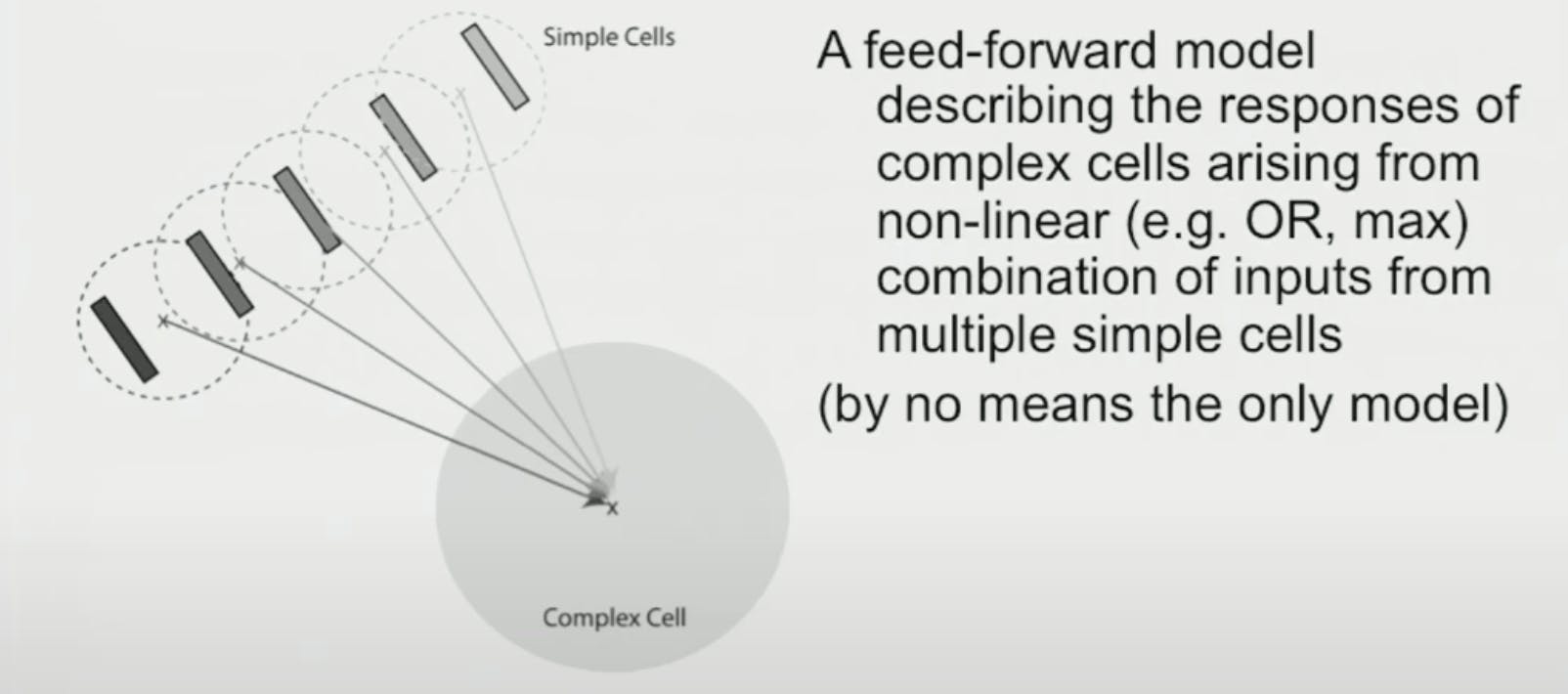
Complex cells
Simple cells have orientation tuning, but if their position is changed (or motion) then it has a drastic reduction in response
Whereas Complex cells have orientation tuning but also have position invariance, they respond even to motion
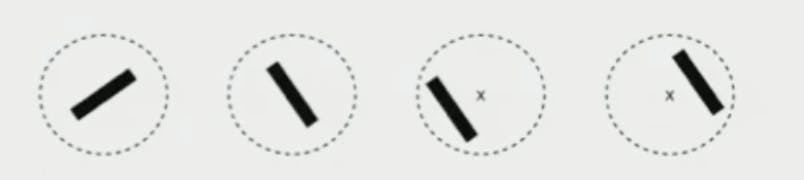
Hubel and Wiesel said we can combine multiple simple cells that are in different orientations and make a complex cell.
Association to Computation
Absolutely, the fundamental operations observed in simple and complex cells within the primary visual cortex (V1) have served as inspiration for various bottom-up hierarchical models in computer vision. Deep learning models, in particular, have incorporated variations of these concepts, especially concerning filtering steps, non-linear operations, and the concatenation of these operations, which contribute to achieving invariance and robust feature representations.
Here's a more detailed explanation:
1. Filtering Steps:
The concept of filtering, akin to the receptive field properties of simple cells, is fundamental in early layers of deep learning models, especially Convolutional Neural Networks (CNNs).
CNNs use convolutional filters that perform operations similar to edge detection, texture recognition, or feature extraction, akin to how simple cells respond to specific oriented edges or textures.
2. Non-linear Steps:
Non-linear operations, such as activation functions like ReLU (Rectified Linear Unit) or sigmoid, are crucial in capturing non-linear relationships between features. These operations are applied after filtering steps.
They emulate the non-linear response properties observed in both simple and complex cells, allowing neural networks to capture more complex patterns beyond linear combinations of features.
3. Hierarchical Models and Invariance:
Bottom-up hierarchical models in computer vision mimic the hierarchy observed in the visual cortex, progressing from simple feature detection to more complex representations.
As information moves up the hierarchy, features become increasingly abstract and invariant to specific variations (such as changes in position, scale, or orientation of objects), mirroring the way complex cells integrate information from multiple simple cells to achieve invariance.
4. Concatenation and Integration:
Deep learning models often involve the concatenation and integration of features learned at different levels of abstraction.
Just as complex cells integrate information from multiple simple cells, deep learning architectures integrate features from various layers, allowing for the creation of more complex and invariant representations of the input data.